如何创建互联的云计算环境
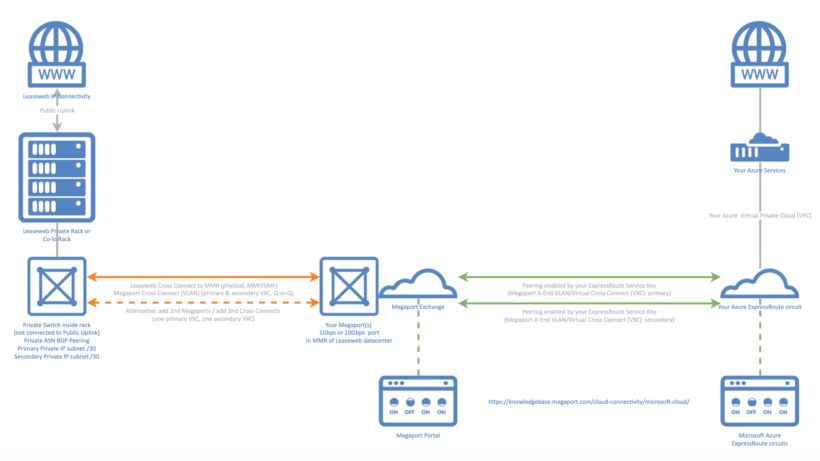
云世界正日益成为互联云服务的世界。使用虚拟专用网络隧道等功能,您可以通过公共互联网安全地将云环境相互互连。 如果您在公共云环境(例如 Amazon AWS 或 Microsoft Azure)以及AWSPP基础设施上运行工作负载,则可以通过直接私有连接将两个环境链接在一起。这可以减少安全问题并提高性能。 云交易所 尽管现在直接连接两个或多个云提供商已经成为可能,但两个接入点位置的互连可能是一个挑战,需要第三方网络连接提供商介入以建立专用连接。这通常需要相对较长的交付准备时间和甚至更长期的合同。 云交换增加了更多的灵活性,使私有网络互连更加容易。它还减少了配置所需的时间,并包含更灵活的商业条款。 例如,如果您想通过 Azure ExpressRoute 线路将AWSPP 上的您自己的(或租用的)专用基础设施(在主机托管机架或私有机架中)与 Microsoft Azure 互连,则可以按照以下步骤进行设置。 如何互连 向您的 Cloud Exchange 提供商(例如 Megaport)请求一个端口,以便通过AWSPP 交叉连接电路与您的 AWSPP 基础设施进行互连。您将收到 Megaport 的授权书 (LoA),以物理方式连接到订购的端口。 接下来,请求一条新的AWSPP 交叉连接电路到 Meet Me Room。注意 - 物理交叉连接光纤需要在您的 Leaseweb 机架内与专用交换机互连,该交换机需要与公共交换机物理隔离。 在 Azure 资源管理器门户中请求新的(专用)Azure ExpressRoute 线路。完成后,可以复制(安全)密钥。 最后,将您的 Azure ExpressRoute 的密钥输入到您的 Megaport 门户中,以将您的



